
Escaping Boring AI
The Camera, The Library, and The Desert

Can AI be creative?
Or framed differently, can we be creative with AI?
The discourse around AI creativity tends to settle into either breathless enthusiasm or dismissive skepticism. The real work happens in the middle ground: understanding these systems deeply enough to find the productive friction points, the unexpected possibilities. In this post I want to dig deeply into creativity and generative AI models from both a philosophical and technical perspective.
Quick plug: If you're interested in exploring how this will impact your organization, we're hosting a free Lightning Lesson Friday August 8th:
Can AI be creative?
Or framed differently, can we be creative with AI?
I'd been noodling on how to deal with this question for some time, but I was able to really crystallize my thoughts in the process of preparing a recent talk for Concept Bureau and some conversations with Jasmine Bina, their intellectually fearless CEO. I think I've come up with a useful and different approach to reasoning about it for people who desire to engage with AI models in a creative way.
We've Had This Problem Before
It's helpful for me to situate this question among earlier debates about what qualifies as creativity or "art." This isn't the first time a technological and scientific instrument has tried to make inroads into the artistic community – it happened before with the advent of photography.

The sculptor Rodin, quoted by Merleau-Ponty in his essay "Eye and Mind," said: "It is the artist who is truthful while the photograph lies, for in reality time never stops." Both were looking at the painting Epsom Derby by the painter Théodore Géricault. The horses in Epsom Derby are painted in an anatomically impossible position. These horses could not exist in this pose—it's not actually how they gallop. But it conveys a sense of motion.
Rodin's bronze sculptures do something similar: his figures aren't anatomically correct humans, but they have an amazing feeling of motion carved into bronze.

They were making these comments right when photography was becoming more popular. They were contrasting this approach with Eadweard Muybridge's now-famous Stanford study of horses in motion, which demonstrated that there's actually a moment in a horse's gallop when all hooves are off the ground—this wasn't clear before then. But despite being more scientifically accurate, the horses appear frozen and still, without the felt sense of motion experienced when viewing Géricault’s painting.

Merleau-Ponty's point was that scientific instrumentation, though perhaps more precisely accurate, is less truthful in terms of human understanding. Today, talking about photography this way sounds odd. But at that time, photography—similar to AI models today—was extremely expensive, difficult to use, quite inaccessible, and largely the domain of technocratic and well-funded institutions connected to structures of power and hierarchy. Painters and philosophers were deeply distrustful and critical of its validity as a medium for understanding deep, human truths.
The painter Cezanne thought of the painter themself as a more appropriate sensor than a camera: "A minute in the world's life passes! To paint it in its reality! And forget everything for that. To become that minute, be the sensitive plate, . . . give the image of what we see, forgetting everything that has appeared before our time."

A clear example of this is Monet, who as you probably know produced many paintings of water lilies. Monet wasn't investigating the most effective way to produce the largest quantity of water lily images. In fact, since photography was becoming prevalent during his lifetime, he could have taken photographs of them if he so desired. Monet instead chose to really treat himself as the camera – the sensor to interpret what the water lilies really looked like. And Monet took this very seriously. The pond he painted wasn't natural—he had it constructed. As he became wealthier and more famous for these paintings, he hired people to dunk the water lilies each morning and skim dust from the pond's surface. He even paved all the roads around his house (quite unusual for that time) to ensure everything was as pristine as possible. Surely, he could have simply seen the dust and painted the lilies without it anyway – but this was not his goal. This way, he could function as a sensor with the most precise interpretation as light entered his eyes and converted through him into brushstrokes on canvas—creating something that wasn't photographically accurate but was nonetheless a true conveyance of his perception.
Today it's obvious that painting continues as an art form despite photography's existence. Most people would likewise agree that photography has entered the art world. We now see these as two different mediums that capture different aspects of artistic truth and creativity.
But we're not there yet with generative AI.
The questions—What is AI? Can it be creative? Is it art?—are still emerging. There's a tension here that rhymes with the tension between painting and photography: forces of economics, frictionlessness, and business are preventing generative AI models from maturing into a medium of creative expression alongside photography, painting and every other instrument and mechanism we think of as capable of creating "art."
It is our responsibility and opportunity as creative people to find ways to escape that and force it back into being a medium of expression.
We Have No Myths to Guide Us

If we've encountered this question before, why must we ask this in a new way? Why can't I just take what Merleau-Ponty said about photography and apply it to AI and be done with it?
The reason is that this technology diverges from past technologies in fundamental ways. We have no myths to guide us. I've searched high and low for any futurist, author, thinker, scientist, mathematician, computer scientist, seer, or prognosticator who, before about 2017, imagined very advanced AI would be much more efficient at creating poetry than at doing arithmetic—which is the case today. I haven't found a single one.
We really don't have any shared stories around this. The stories we have about robotics, AI, and machine intelligence don't describe what we're confronting today. We're struggling even with the words to talk about it. Something that does a thing that looks like thinking—but we know it's not how humans do thinking. So do we just argue about whether it's really thinking, or do we call it something new like "thunking" or "grokking"? We're all learning about this together, and all of us have a role in creating how we make sense of it. There are no past guides.
Can AI Be Creative?
So can AI be creative? Can I be creative with AI, and how can I do this better?
To answer this question, we need to define creativity. I think a good definition for what we want to analyze is "creativity means producing the meaningfully new."
Television static produces endlessly new, random combinations, but not everything new is meaningful -- I wouldn't call this creativity, which is why I frame it this way. Singing a familiar song may be meaningful, but it isn’t new – I also wouldn’t call this creativity. Singing a song that is both meaningful and new is undeniably creativity. If we accept this definition, we can decompose our investigation into two parts: Can generative models make something new? And can generative models make something meaningful?
I want to demonstrate why the answer to the first question is incontrovertibly yes – in two specific ways. The answer to the second question should be a separate essay entirely, but I will touch on some initial thoughts at the end and point to further directions.
Deliberate and Controllable Randomness
When you go into ChatGPT today and type "write an ode to a dog," you get: "Ode to a dog! Oh, steadfast soul with silken ears, who greets the dusk when dawn and cheer..." Ask for another, and it says, "Oh, steadfast heart! With paws of grace you greet the dawn..." Then another: "Oh, steadfast heart on four swift paws..."
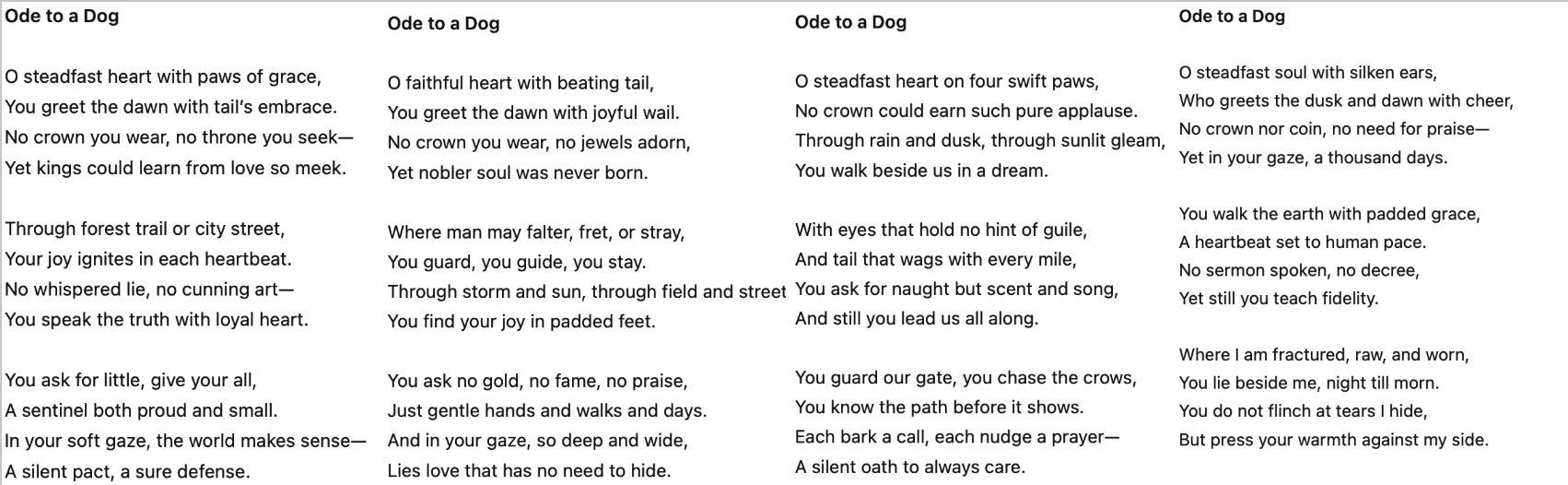
Apparently dogs are steadfast, and odes always start with "O."
This is clearly not the only kind of ode that can exist about a dog. We'll all agree this is boring. But what I want to emphasize is that it doesn't have to be this way—this boring repetition was very specifically designed.
In fact, it takes billions of dollars, years of research, and extremely rare, specialized talent to make these models boring. It's incredibly difficult to make them boring. They aren't naturally boring.
The fact that they are boring also isn't a bad thing. When I'm at work writing an executive summary or sending routine emails, I want boring. I want it to do the thing reliably. If that means dogs are only steadfast and odes always start with "O," I'm fine with that. There are good reasons for this. It's a perfectly acceptable and desirable for business use, but it's unacceptable for creatives.
But consider the other extreme: all outputs are equally likely. Any combination of letters and numbers is equally likely. Jorge Luis Borges describes this in "The Library of Babel"—a vast library containing every combination of letters of a certain book length. By definition, this library must contain an exact description of the moment of your death, an exact description of what you did today, and a thousand variations in between. But most of the library is a desert of gibberish.
He writes: "One book which my father once saw in a hexagon in circuit 1594 consisted of the letters MCV perversely repeated from the first line to the last. Another much consulted in this zone is a mere labyrinth of letters whose penultimate page contains the phrase 'O Time, thy pyramids!' This much is known: for every rational line or forthright statement there are leagues of senseless cacophony, verbal nonsense, and incoherency."
The most extreme determinism is a calculator (or just most pre-LLM computing methods), where any given input has exactly one output. On the other hand, we have the desert of complete randomness where very little meaning ever appears. In the middle, we have language models.
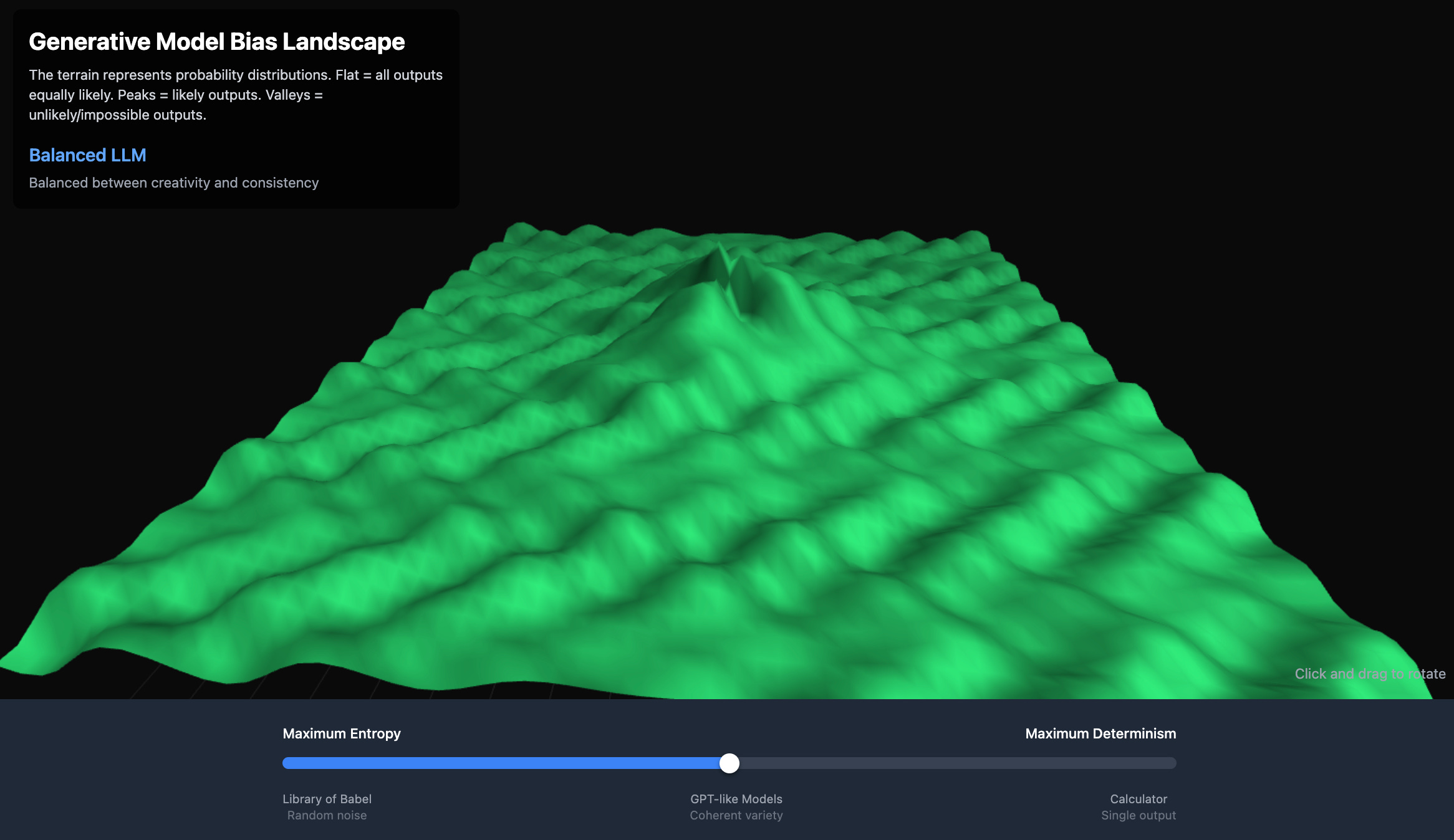
Click here for interactive version: https://claude.ai/public/artifacts/1be84bf8-9945-4672-9bf7-7de43077fbdc
Language models are like maps. They're literally spaces where words that co-occur or are similar cluster together, while different or infrequent word combinations are far apart. Today's models have thousands of dimensions and trillions of data points.
This is how models map language and thinking. They get here through training.
How Models Are Trained to Be Boring
You train a model by collecting lots of data—usually all of the internet, plus some books, plus other material. But what happens next is quite extraordinary, and understanding it helps explain why models end up so boring.
The training starts with a model that knows absolutely nothing—imagine the Library of Babel, where every possible combination of letters is equally likely. At this stage, if you give it the beginning of a sentence like "The cat sat on the," it might respond with "purple elephant mathematics Tuesday" or just random characters. Complete nonsense.
The training process is like teaching a child language, but at an incomprehensible scale. You feed the model billions of sentences from the internet, and for each one, you play a game: hide the last word and ask the model to guess it. "The cat sat on the [BLANK]." The model guesses randomly at first—"strawberry," "democracy," "zzxqw." Wrong. You show it the real answer: "mat." It adjusts its internal connections slightly. You do this again with "The dog chased the [BLANK]." It guesses "mat" (because that worked last time). Wrong again. The answer is "ball." It adjusts.
After billions and billions of these corrections, patterns emerge. The model learns that after "The cat sat on the," words like "mat," "chair," or "floor" are more likely than "democracy" or "purple." It builds up an incredibly complex map of which words tend to follow other words, which concepts relate to each other, which writing styles match which contexts.
When you're done with this process—which takes months and costs millions of dollars in computing power—you get what's called a base model. This is what all models were like back in the GPT-3 DaVinci days. They act like fancy auto-correct. Whatever you start, they finish. If you say "the capital of France is," it continues: "...a city with a rich history and culture, and is known for stunning..." You can't come in and say "write a blog about France." It gets confused. It doesn't know what a command or question is.

If you typed "Write me a poem" into a base model, it wouldn't write you a poem. Instead, it might continue: "Write me a poem,' she said, her voice trembling as she handed him the pen. The afternoon light..." It's just continuing what it thinks is a story where someone asked for a poem. It doesn't understand that you're giving it an instruction.
Basically, it's playing this game: "What if I found this on the internet? What would come next?" One way to hack this is by giving it examples. Give it three Pablo Neruda poems, then start a new poem with "Ode to a dog," and sometimes (but not always) it'll start writing a poem about a dog.
This is where instruction tuning comes in—a second phase of training that fundamentally changes the model's behavior. Now you collect a much smaller but very specific dataset: thousands of examples of humans giving instructions paired with appropriate responses. "Write an essay about dogs" paired with an actual essay about dogs. "Summarize this article" paired with a summary. "Answer this math problem" paired with the solution.
Through this process, you teach the model to recognize when it's being given a command versus when it's just completing text. But here's the crucial part: Nothing about training on raw internet data naturally produces something that acts like a helpful human assistant. That's a very specific choice made by the companies building these models.
Every round of fine-tuning involves tradeoffs. When you optimize a model to be better at following instructions, you're changing its probability distributions. The base model has a very wide, relatively flat probability distribution over possible outputs—many different continuations are reasonably likely. But instruction tuning sharpens certain peaks, making helpful, coherent responses much more likely, while suppressing the long tail of weird, unexpected possibilities.
The strange word combinations, the unexpected transitions, the grammatical experiments that a base model might produce—these become exponentially less likely after instruction tuning. The model still contains all that knowledge, but accessing those weirder spaces becomes much harder because the probability landscape has been reshaped to favor conventional, helpful responses.
Then you do more fine-tuning for things like reasoning, so it's better at processing CSVs or doing math or using tools. Then you collect more data, fine-tune again, and repeat this process over and over. Each time it gets better at some things—usually business-relevant tasks—while the probability space continues to narrow. The model becomes more reliable, more useful, and inevitably more boring.
Temperature: The Randomness Control
Why am I telling you all this? Because what you get here is much less reliable and much weirder. Importantly, you can play with something called temperature.
Temperature is the randomness injected into the model when you run it. You always inject randomness. This is why it's almost impossible (unless you're really trying) to get the model to completely replicate something that existed before.
Because they've exposed the temperature setting, I can turn it way down. When I do, I get something very repetitive and flat: "I have a dog like no other dog has ever been before, with a better pedigree, with a better coat, with a better bark, with a better tail, with a better nose, with better paws, with better eyes, with better ears." It gets into repetition and rhythm.

If I turn the temperature way up, I get something close to the Library of Babel—complete nonsense that goes entirely off the rails.

All the sense exists in the middle, around 0.73 on this particular model. Here, probably three out of five times I get pretty good poems. Weird stuff appears—like it says "by Pablo Neruda, translated by Ms. Pendon." This isn't a real Neruda poem. It's hallucinating. But in this case, that's good.

With high temperature settings, you're less like a bonds investor getting reliable returns every time, you’re more like an angel investor hoping that 1/100 investments will produce something amazing. Instead of always getting a boring poem, you might get one thing that's not a poem, three mediocre poems, and one amazing poem.
This temperature variable is still there with models in ChatGPT, although the setting isn’t surfaced in the interface. There's always randomness being injected, so there's always something new being created. The extent to which it's boring or not is not emergent but very deliberately constructed.
Is this hard? Is this complicated? Are you having enough trouble learning to use the normal default ChatGPT? Yes. Is learning how to find other interfaces and models where you have more control necessary? Yes. As a creative person, you must find these places. You must get out of the standard ChatGPT models and find ways to turn up the temperature. But you must be prepared – in return for access to unexpectedly beautiful results, you get unreliability, and a lot more meaningless garbage to wade through.
Accidental and Emergent Consistencies
Some of you may remember the ancient days of early image models—an unfathomable two years ago—when we had lots of mistakes from them. You'd get the phenomenon of too many fingers or arms or hands.

This phenomenon wasn’t a duplication from the models’ datasets. It didn't happen because the model creators accidentally put too many images of people with three hands in the training data. This was something new—accidentally new. It's an emergent newness. This doesn't mean it's meaningful, but it is new.
I'd like to shift how we think about this from seeing it as a problem with AI models, something to be fixed, a signal we should wait until AI gets better. Instead, I’d like to think about these as artistic affordances.
Imprecision is part of what makes something a creative medium instead of a scientific instrument. It's the conversation between me and the paint, or the struggle between me and the cloth, that makes an art piece emerge. I'm not waiting for more accurate, controllable paint before I start painting. I'm not hoping someone will create more frictionless cloth. You use a material as it is, and its limitations as much as its affordances define what you make with it.
Often the inaccuracies or accidents of a technology become a core part of how music or art is made with it. Think about the record scratch, which started as accidental noise from a record player and became a fundamental element of later music genres. Or lens flare, which people struggled to avoid with analog cameras but is now a standard filter in every precise digital phone camera. Why? Because something about these inaccuracies, these mistakes, evoked a meaning that we couldn’t express before. Through our struggle with them, we encoded them with so much meaning that we wanted to reintroduce them deliberately, even when we later had the option to escape it.
I used the prompt "watercolor painting marathon runners" in different image generators. The most recent Midjourney version 6.1 produces a nice watercolor of runners. When I think about a watercolor of marathon runners, this is more or less what I'd imagine. It's very coherent, very expected, and therefore boring.

My favorite image generator I've ever used is GLIDE-3 XL from 2022. It was what you might call very bad at making images that look like things—but bad in a way I find artistic. The images are distorted and broken, often disturbing when using faces or body parts.



But I'd like to change how we think about this. What if, instead of thinking of these as broken things, we thought about what we're feeling here? What is specific to this medium, to this AI-ness? What would happen if, instead of moving away from it, I dove more fully into it? What if I emphasized it? I even mean this about the inimical em-dashes and emojis of AI writing too. I'm using images here because it's easier to make the point, but the arguments apply equally to writing. What if I used so many em-dashes and emojis that I could barely read the text? What about the AI writing actually makes me laugh, or feel irritated, or roll my eyes in a such a way that I might replicate it even were I writing without AI assistance?
I'm not trying to get you to ignore the parts of AI that don't work, or to sell yourself on AI art being great. I'm trying to get you to look for the mistakes that accidentally get at something interesting and meaningful that we could add to our repertoire of trying to understand and communicate fresh nuances of this often inexplicably weird experience of being alive.
In other words, what is the lens flare of AI image models? What is the record scratch of AI music generators? What is the footnote of AI writing?
Just for fun, I went into today's image generator in ChatGPT, which is very precise, and asked it to reintroduce the wrong number of fingers and distortion. It came out interesting. It's actually quite hard for it to make the wrong amount of fingers—it's like it's been shoved out of that part of the landscape. But it tries to introduce it, bringing back some of that disturbing weirdness in a more controlled way. Maybe its meaningful, maybe not.

The secret to new ideas in generative models lies in their mistakes. As you work with them, don't only spend time critiquing them, waiting for them to get better, or dunking on them on LinkedIn. Seek out their inaccuracies and try to find the beautiful ones. Covet their consistent violations, encourage their hallucinations, and make time for their glossolalia. As a creative, this is where the greatest fruit lies for us.
Accidental consistency, deliberate variation. What happens if you lean into the behavior of the model, increase the AI-ness? Where would this take you?
Can They Make Something Meaningful?
The next question is: can they make something meaningful? This is more of a separate essay, but I'll leave you with the idea that truth and meaning are both information and process, and these differ for each group.

There's an ancient compendium of religious interpretation called the Talmud, where you have the original text (the Torah, similar to the Old Testament) and layers of interpretation around the edges. Scholars over thousands of years have written thousands and thousands of pages of interpretation around it. There's the truth in the middle, then its interpretation.
This process of exegesis differs across many groups. In Christianity, you have hierarchical Catholicism; Episcopalianism and the Anglican Church with bishops, clergy, and laity in a flatter structure; and Quakerism, which is entirely flat.

Each community – artistic, religious, professional – has its own processes for encoding meaning into media. Each group has a process, implicit or explicitly, for deciding whether something is meaningful. These processes of analysis can be augmented with generative models…although it is still quite hard to do well. Perhaps in a later essay we’ll explore this more fully.
The Path Forward
There isn’t one answer to where, between you and your medium, you should situate control and randomness. Take Jackson Pollock's painting – he gives up a lot of control to his paints and other physical forces outside himself. Or Sol Lewitt, who maintained precise control over the process but not the visual outcome. Like Monet, who wanted 0% randomness on the water lily pond. He wanted it precise, pristine, with no dust. He wanted all variation to emerge purely from his mind, hand, and brush. Someone else might see it differently—they might want an exact photorealistic rendition of a very chaotic scene. These options also arise with generative art. What makes it make more or less sense relates to the meaning you're trying to convey.
Which is correct? Both are parameters you could define and seek out, depending on what you're trying to say to the viewer.
There aren’t any answers or guides to this yet, and even fewer clues. But its our responsibility as creatives to dive into this zoo and find beauty there, to force generative AI back from the desert of boringness into the realm of the…
