
When Knowledge Architecture Becomes Product Architecture
The Design Choices of Automating Organization's Tribal Knowledge

This week we launched the charitable giving platform we built with Give Alliance. On the surface, it looks like another chatbot. It helps donors navigate charitable giving decisions by answering pointed questions. Behind the familiar chat format, however, lies a bigger story — a development challenge to capture years of institutional expertise and translate it into conversational logic. Using Give.org as a case study, I want to use this opportunity to delve into the steps and collaborations involved in turning institutional craft into conversational intelligence.
The cross-roads which I map in this article are analyzed in full depth in our comprehensive course. Our free 30-minute lightning lesson provides a bite-sized insight from this course, examining how to specialize agents for institutional work without overengineering them. Join to attend the lightning lesson through the link below.

Many off-the-shelf AI implementations treat organizations like document repositories — upload PDFs, get answers back. AskGive represents a different approach. Give.org has developed a particular approach for building donor trust and evaluating charitable organizations. This isn't just accumulated information — it's cultivated judgment about how to categorize donor needs, when to provide general guidance versus specific recommendations, how to maintain neutrality while being helpful, and so on. The question wasn't whether AI could access this knowledge, but whether it could apply this in a thoughtful manner characteristic of Give's methodology.
The Architecture of Institutional Intelligence
The method for mirroring Give's approach in a generative tool has many dimensions, of which the user has no awareness while conversing with the tool. For one, it is not a single set of instructions sent to an LLM model. Rather, it consists of nine different chatbots and an AI router that chooses which of them to delegate the user's request to.
This structure reflects how a representative at Give would handle a question. They would first ask themselves: is this a question about philanthropy, or a specific charity, or our organization? How they decide to shape their response, what information they will rely on will differ vastly depending on how they categorized the question.
Through a series of structured interviews, we arrived at the nine categories that seemed to faithfully replicate the mental sorting process. Once we automated this cognitive step, the finer art of tuning the instructions began. As is often the case with these kinds of projects, the final 10% of behavior tuning demanded the most nuanced understanding of organizational dynamics and required many cycles of fielding feedback from experts, tweaking instructions, and returning for more feedback.
The difference between the chatbot response "Best education charities are X, Y and Z" and "Here are best practices to evaluate education charities yourself" represents the gap between information delivery and institutional methodology. The first treats AI as a search engine; the second embodies Give.org's approach to donor education — always teaching evaluation frameworks rather than making recommendations.
Achieving this distinction demanded dozens of micro-adjustments that only someone steeped in Give's methodology would recognize, yet these subtleties fundamentally shape how users experience the tool. Much work went into calibrating word choice and positioning to balance authoritative information with appropriate caveats—confident enough to be useful, measured enough to remain ethically responsible. The system learned to position Give.org's methodology as distinctive without casting judgment on philanthropies or disparaging other evaluators. We also structured responses to guide users through evaluation processes rather than delivering conclusions, requiring the model to consistently choose pedagogy over efficiency. There were more interpretive considerations, too, like making sure the tool would never frame a charity's 'Did Not Disclose' status as inherently negative, recognizing that non-disclosure often reflects organizational capacity rather than poor practices.
In a stochastic tool involving LLMs, there is no clear finish point when you know that the model is faithfully teaching when it needs to teach and recommending when it needs to recommend. We had to test at length to make sure that for charity-specific inquiries, the prompts employ strict neutrality protocols that actively prevent comparative language or rankings, channeling responses along Give.org's ethical framework for charity evaluation. Unlike debugging methods of old, this is a statistical process. The only way to verify that we met the goal is by throwing dozens of pertinent questions at the model, taking a slightly different angle with each, and calling it a day if all but one returned the desired response.
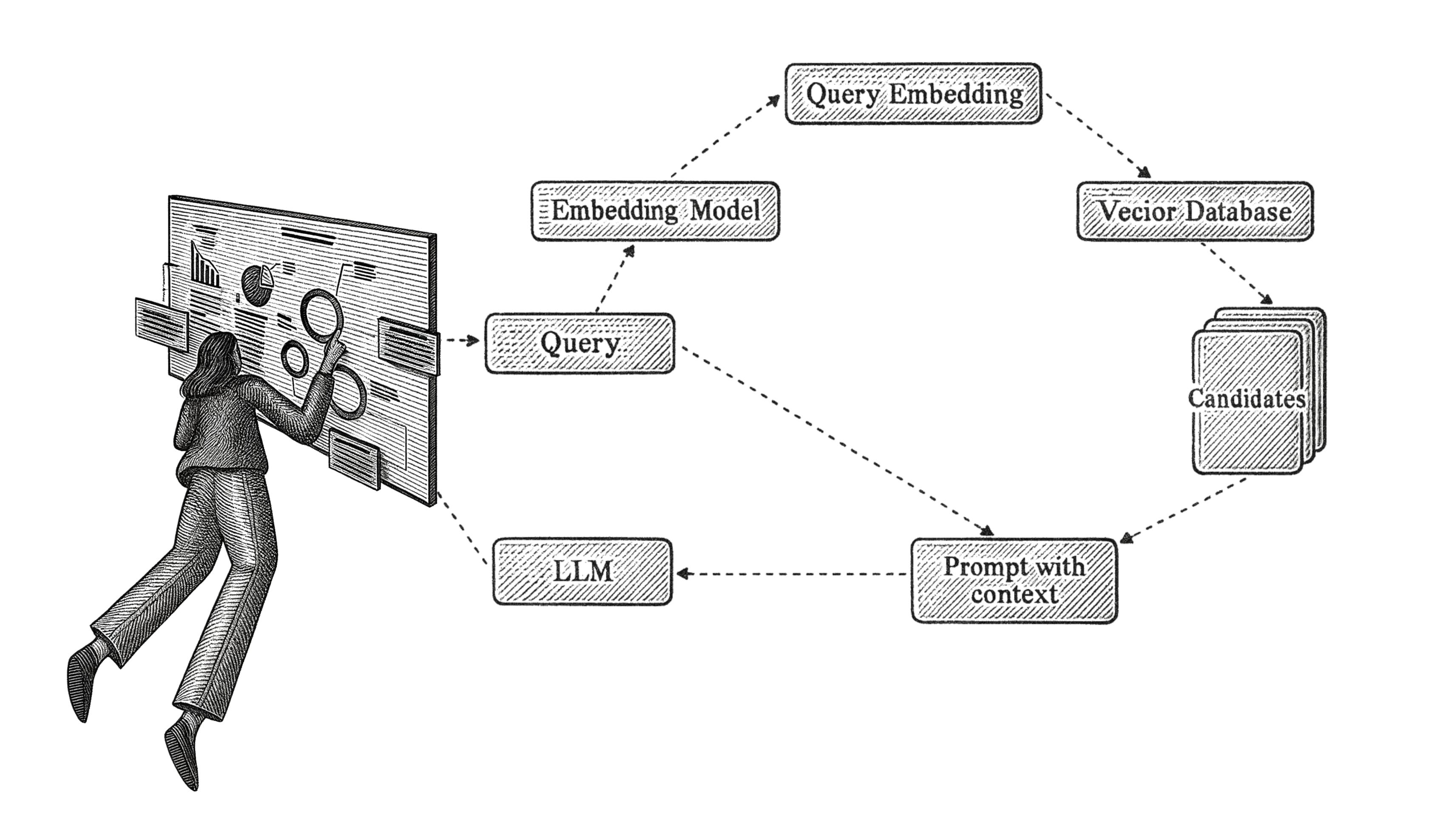
Data retrieval presented a standalone challenge to address. How we retrieved relevant information from Give's massive charity and content databases was a distinct LLM operation of its own. Relying solely on terms the user explicitly mentions often fails to capture relevant content in the database. So we asked an LLM to first offer synonyms, related concepts, terms and ideas. As a result, questions about "which charities to support" thoughtfully sift through verified charity data with retrieval parameters tuned to address the particular angle of the user's inquiry.
We had to consciously discuss each of these decision-making points, making sure the client was informed of the choices made, but not buried in the technicalities. Shaping the partnership to evoke the required insights has turned into an art of its own, and something we have been honing over the years alongside the technical know-how. Articulating tacit practices and bringing implicit approaches to the surface represents a critical challenge all organizations must address to maintain their distinction in an emerging landscape defined by intelligent agents. Whether it's legal firms maintaining consistent counsel across cases, medical institutions ensuring diagnostic consistency, or consulting firms preserving methodological rigor across engagements, the clarion call is the same.
The New Landscape of Institutional Intelligence
Every organization sits on decades of accumulated expertise that exists primarily in the minds of its people. For the first time, we can channel this distributed wisdom as a coherent whole rather than as standalone insights. This transformation of distributed organizational wisdom into coherent AI systems is what we explore in our course. Through hands-on development, we teach leaders and project managers how to build knowledge architectures that preserve institutional character while enabling new forms of scale and interaction. Building these systems is hard work, but from experience we know it to be very rewarding, and teaches us more about ourselves than about the technology that serves as conduit.